Zero-shot image classification with OpenAI's CLIP
In recent years, there is a trend in the field of Deep Learning to develop models that can understand multiple modalities, such as texts, images, sounds and videos. Google’s Gemini is the latest example of this trend. These models open up new possibilities for AI applications, such as zero-shot learning, where the model can perform tasks without any training data. In this post, we will explore OpenAI’s CLIP, a model that can understand images and texts, and use it to perform zero-shot image classification on the Animal Faces dataset.
Introduction to CLIP
CLIP (Contrastive Language-Image Pre-Training) is a model developed by OpenAI that can understand images and texts. The model is trained to predict which of the image-text pairs in a batch is the correct pair. The model is trained on a dataset of 400 million image-text pairs, which are collected from the internet.
Here is the model architecture from the paper:
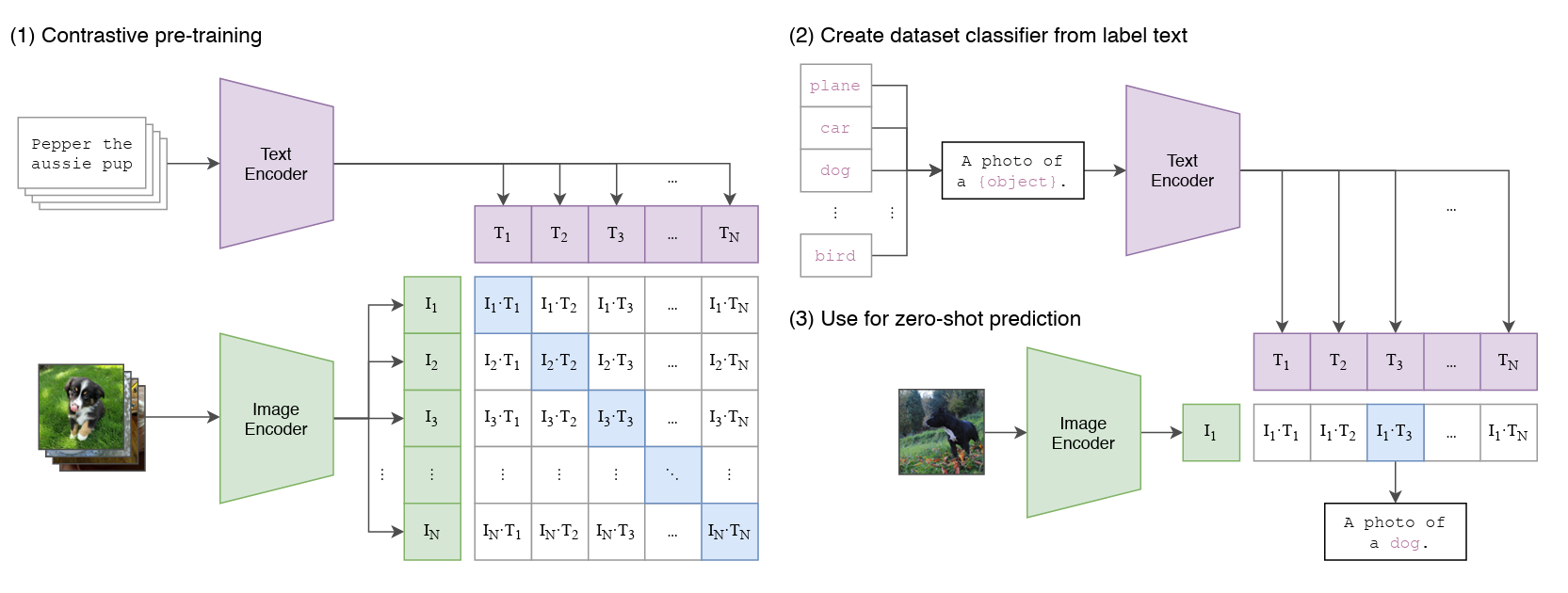
It has 2 main components:
- Image encoder: It takes an image as input and encodes it into a sequence of vectors. In the paper, the authors experimented with ResNet and Vision Transformer as the image encoder.
- Text encoder: It takes a text description as input and encodes it into a sequence of vectors. In the paper, the authors experimented with CBOW and Text Transformer as the text encoder.
The outputs of the image and text encoders are then used to compute the cosine similarity between the image and text representations. The cosine similarity is a measure of how similar two vectors are in terms of their direction. It is calculated as follows:
where and are the two vectors and and are their magnitudes.
The model is trained “to maximize the cosine similarity of the image and text embeddings of the real pairs in the batch while minimizing the cosine similarity of the embeddings of the incorrect pairings”.
The Animal Faces dataset
The Animal Faces dataset also known as Animal Faces-HQ (AFHQ), consists of 16,130 high-quality images at 512×512 resolution.
There are three domains of classes, each providing about 5000 images. By having multiple (three) domains and diverse images of various breeds per each domain, AFHQ sets a challenging image-to-image translation problem. The classes are:
- Cat
- Dog
- Wildlife
Link to the dataset: Animal Faces-HQ
Loading the CLIP model
OpenAI has released the pretrained CLIP model. We can load the model using the transformers library.
1 | |
Zero-shot image classification
Download the Animal Faces dataset from the link provided above and extract it. The dataset is organized into three folders, one for each class. We will use the glob library to get the paths of all the images in the dataset.
1 | |
Run the above code give us the following result:
1 | |
Nice! We achieved an accuracy of 86% by just using texts to classify images. This is the power of zero-shot learning.
But the 58% recall for the “wild” class is not good. Let’s see some examples of misclassified images.
1 | |



As we can see, the model is misclassifying images of wild animals as cats and dogs. These animals, such as lions, wolves, and tigers, share some visual similarities with cats and dogs, which makes it difficult for the model to distinguish them.
One way to improve the model’s performance is to change the text descriptions to include more specific details about the animals. For example, instead of “a photo of a wild animal”, we can use “a photo of a lion” or “a photo of a tiger”. This will help the model to better understand the differences between the classes.
Change the text descriptions as follows:
1 | |
Run the code again and we get the following result:
1 | |
Wow! We achieved an accuracy of 98% and improved the recall for the “wild” class to 100%. This is a significant improvement over the previous result.
Conclusion
In this post, we explored OpenAI’s CLIP, a model that can understand images and texts, and used it to perform zero-shot image classification on the Animal Faces dataset. We achieved an accuracy of 98% by just using texts. This demonstrates the power of zero-shot learning and the potential of models that can understand multiple modalities.
Howerver, while the model performed well on this dataset, it may not perform as well on other datasets. For example, if the task is to classify images of specific breeds of dogs or cats, the model may not be able to distinguish between them based on the text descriptions alone. It heavily depends on how the model was trained and the quality of the text descriptions.
In such cases, it’s still better to use traditional supervised learning methods to train a model on a specific dataset. But zero-shot learning can be a useful tool when you don’t have enough labeled data for a specific task, or we can use it as a starting point for labeling data.
References
- Radford, A. et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. arXiv preprint arXiv:2103.00020. Link